
Introduction
At Nordlys Labs, we built Hypernova: a Mixture of Models router that dynamically selects the optimal LLM for each task. Rather than routing all requests to a single model, Hypernova learns which models excel at which problem types and routes accordingly.
The key insight: no single model is the best at everything.
Model Specialization: The Hidden Opportunity
We analyzed the SWE-bench Verified leaderboard:
| Model | Tasks Solved | Success Rate |
|---|---|---|
| Claude Opus 4.5 | 372 | 74.4% |
| Gemini 3 Pro | 371 | 74.2% |
| Claude Sonnet 4.5 | 353 | 70.6% |
At first glance, Opus appears to be the clear winner. The naive approach would be to route all requests to Opus.
This misses a critical pattern.
Analysis of per-task results reveals: "65 tasks that Opus failed were solved by other models." Specifically, 23 tasks that Opus failed were solved by Sonnet. The reverse is also true: 42 tasks that Sonnet failed were solved by Opus.
This demonstrates that models have complementary strengths. The ceiling for a routing system that selects the optimal model per-task is significantly higher than any single model's performance.
The Solution: Cluster, Learn, Route
Hypernova operates in three stages: semantic clustering of problems, learning per-cluster model performance, and routing inference.
Step 1: Semantic Clustering
We derive clusters from a general coding dataset by embedding each problem description using a sentence transformer model, producing dense vector representations that capture semantic meaning. Problems with similar underlying structure (e.g., authentication bugs, performance optimizations, API integrations) cluster together in embedding space, even if they use different surface-level terminology.
We apply clustering to partition the embedding space into discrete regions. Each cluster represents a category of semantically related problems. These clusters, learned from general coding data, transfer effectively to domain-specific benchmarks like SWE-bench.
Step 2: Per-Cluster Performance Profiling
Using evaluation data from SWE-bench, we compute each model's success rate within each cluster. For every problem in the training set, we record which models solved it and aggregate these results by cluster assignment.
The results reveal significant performance variance across clusters.
In some clusters, Gemini achieves 100% success rate while Sonnet only reaches 70%. In other clusters, Sonnet leads at 81% while Gemini drops to 76%. This variance is not random: it reflects genuine differences in model capabilities across problem types.
Key observation: Each model has distinct strengths and weaknesses that manifest consistently within semantic clusters.
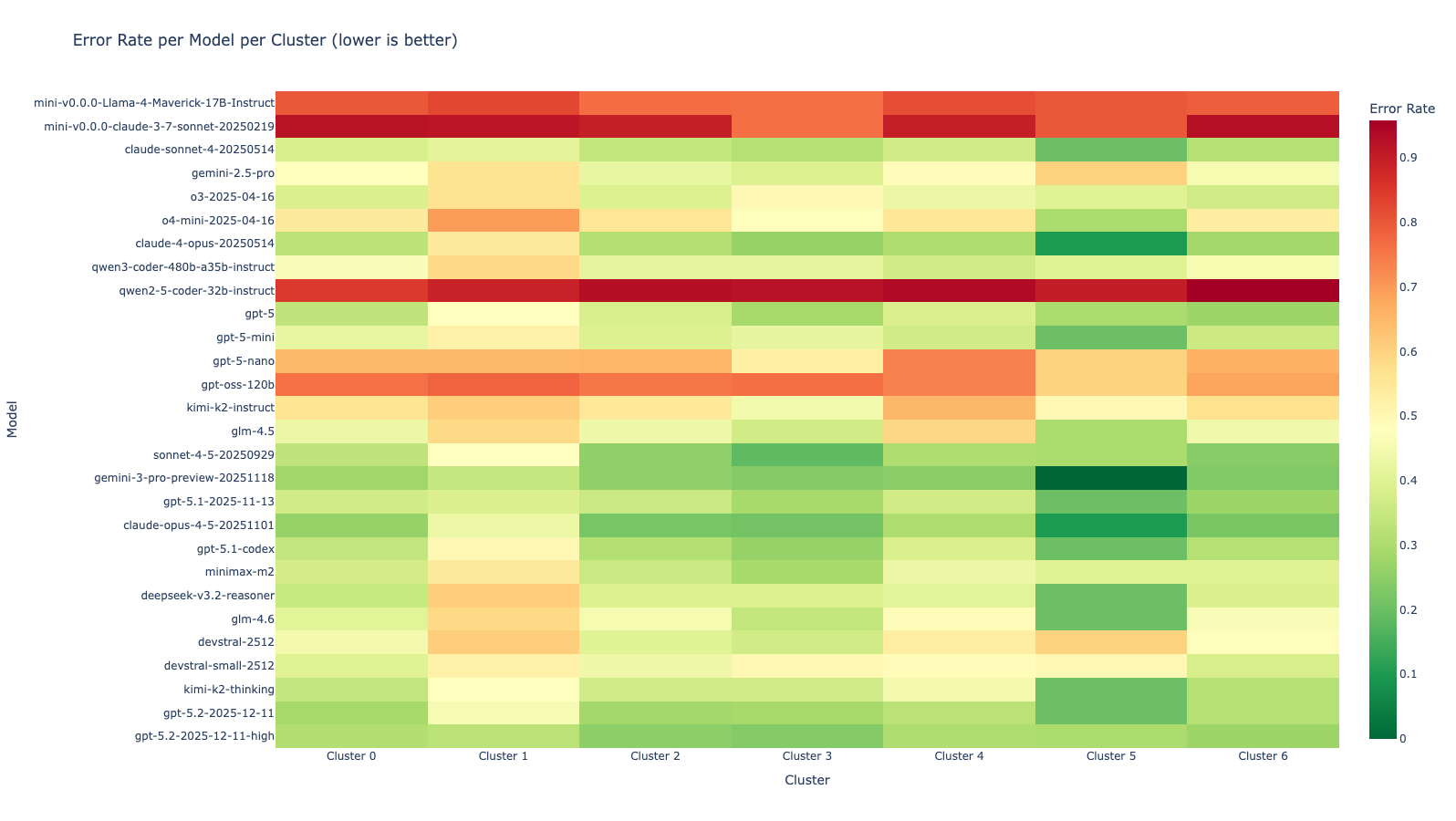 Model performance heatmap across clusters
Model performance heatmap across clusters
Step 3: Inference-Time Routing
At inference time, when a new problem arrives, Hypernova executes a simple pipeline:
- Embed: Generate a vector representation using the same sentence transformer
- Classify: Find the nearest cluster centroid via similarity search
- Route: Select the model with the highest historical success rate for that cluster
This approach has minimal latency overhead: embedding and nearest-neighbor lookup complete in milliseconds, while the actual LLM inference takes seconds to minutes.
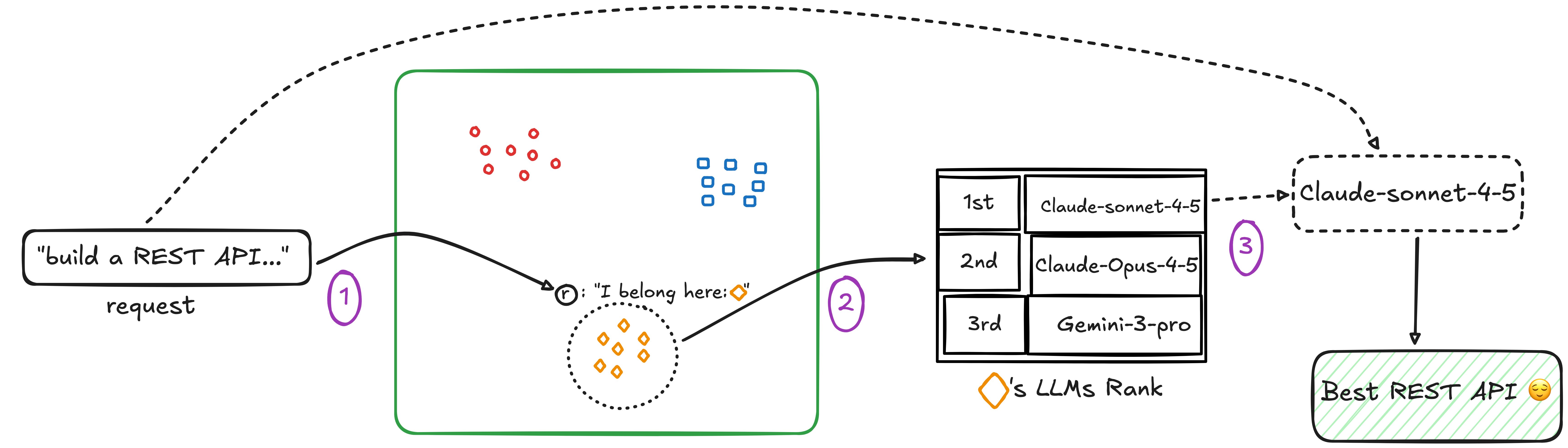 Hypernova routing flow
Hypernova routing flow
Evaluation Results
We evaluated Hypernova on the full SWE-bench Verified benchmark, comparing against single-model baselines.
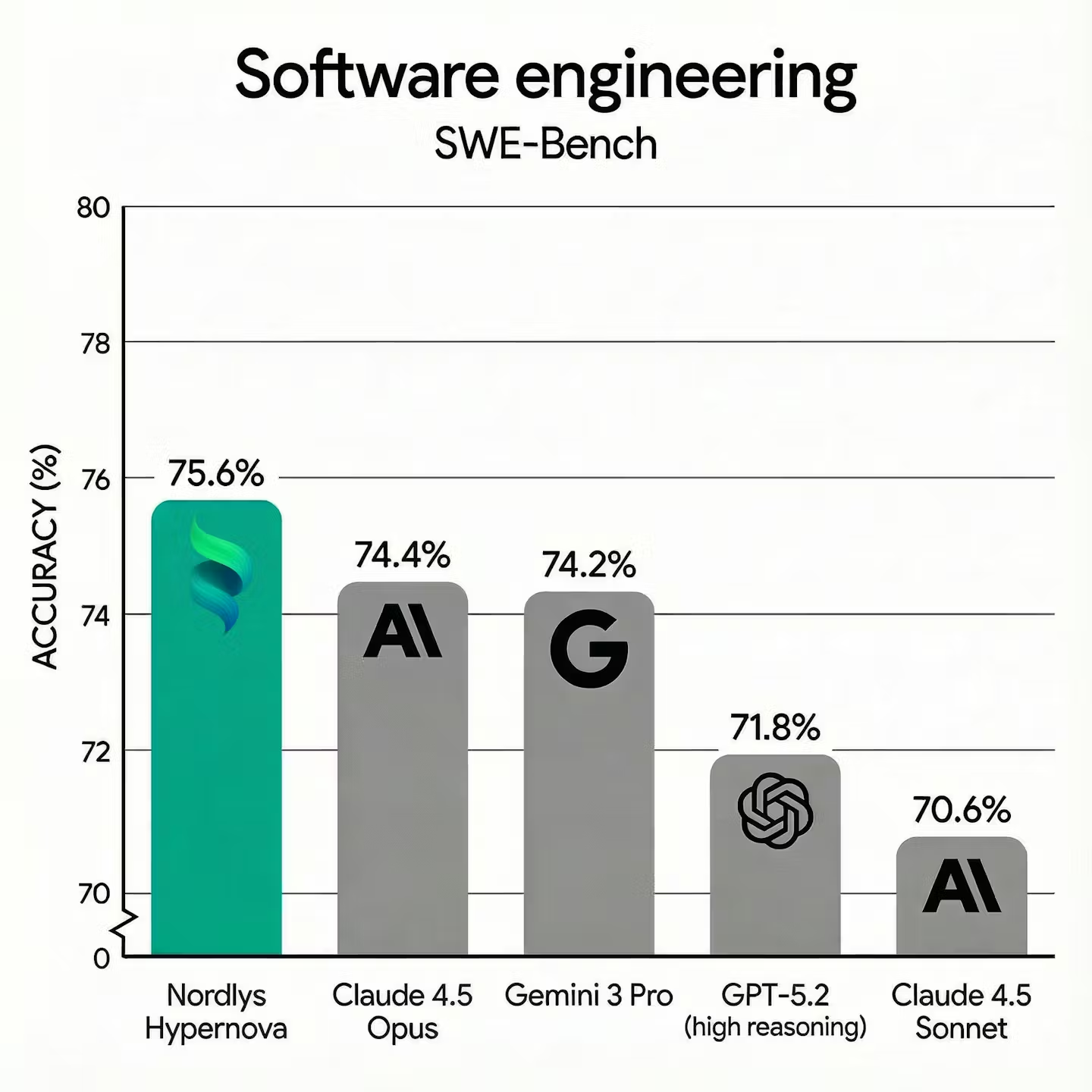 SWE-bench results comparison
SWE-bench results comparison
Future Work
This is an initial proof-of-concept. Several directions for improvement:
- Expanded training data: More evaluation data enables finer-grained clustering and more reliable performance estimates
- Dynamic model pool: As new models are released, we can profile them against existing clusters and integrate them into the routing table
- Cost-aware routing: Incorporate model pricing and latency into routing decisions for cost-performance optimization
Built by the Nordlys Labs team
Inspired by: Universal Routers for LLMs